Hi, and welcome to this lesson about queuing structures.
In the previous lessons, we’ve looked at the two main algorithms for graph traversal, DFS and BFS, and how to build and use routing tables to navigate their corresponding graphs. In this lesson, we’ll see how these algorithms can be implemented in practice, using queuing structures.
A queuing structure is a memory structure that can be used to manage priorities between tasks.
For example, imagine that we have a list of documents, and we need to decide the order in which we will process them. Queuing structures can be used to store the documents and manage the priority between documents.
There are only two operations that can be performed when using a queuing structure. Namely, adding (or pushing) an element, and removing (or, popping) an element.
I’ll now introduce two queuing structures that can be used to manage priorities in different ways.
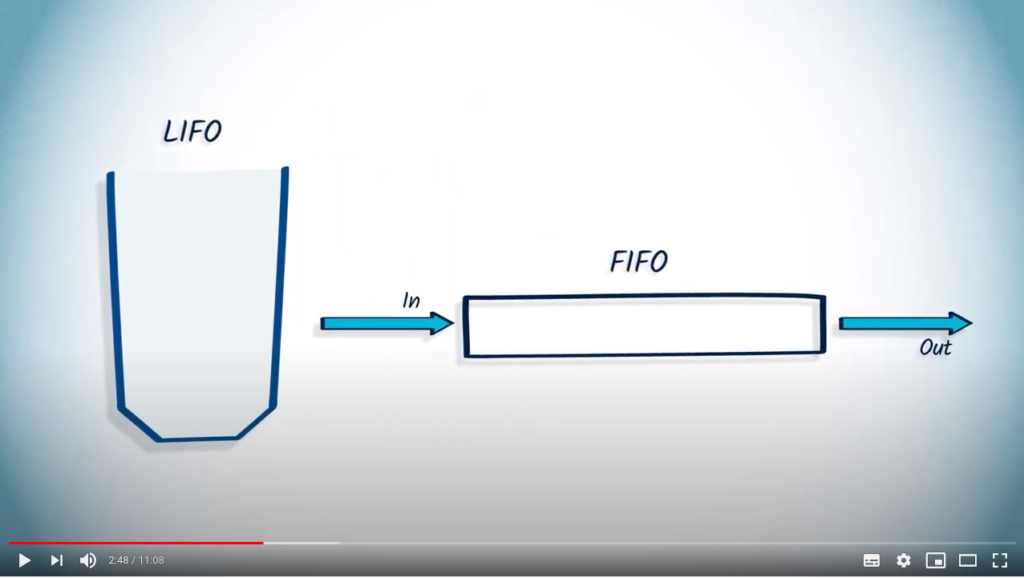
Stacks / LIFO / Last-In First-Out
A stack, which is known as a Last-In-First-Out, or LIFO for short, is a memory structure for which the last element added in the stack is the first one that will be removed.
Let’s imagine a list of documents we have to process. Using a LIFO means putting all the documents in a pile, or stack. You can only pick up the document on the top of the pile, which was the last one added.
Queues / FIFO / First-In First-Out
On the contrary, a queue, which is known as a First-In-First-Out, or FIFO for short, is a memory structure for which the first element added will be the first one to be removed.
Imagine it as a queue in a shop. Customers are served on a first-come, first-served basis.
A unified algorithm for graph traversal
A queuing structure can be used to manage the priorities with which we examine vertices in a graph when performing graph traversal.
When exploring a vertex, a queuing structure can be used to store the neighboring vertices, but only if those vertices weren’t previously explored.
By repeating this principle until the queuing structure is empty, we obtain a DFS if we choose to use a LIFO, and BFS when we use a FIFO.
Indeed, when using a LIFO, we first explore the last vertices that were added to the queuing structure, and thus keep following the last direction. However, when using a FIFO, we first explore the first added vertices, and thus proceed with increasing hops from the start.
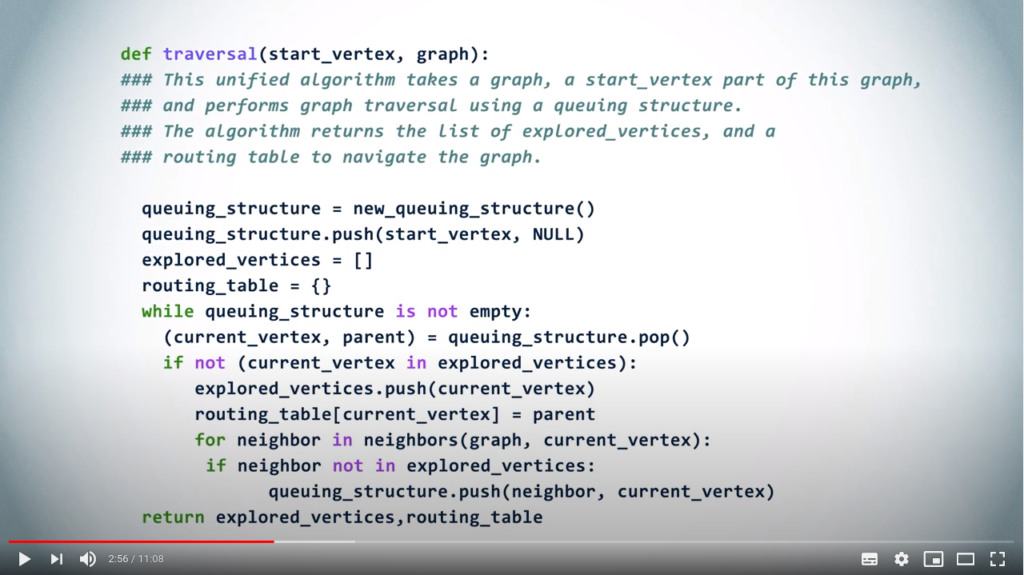
The following unified algorithm will function for both a BFS and a DFS by simply changing the queuing structure. In other words, using the LIFO for a DFS, and the FIFO for a BFS.
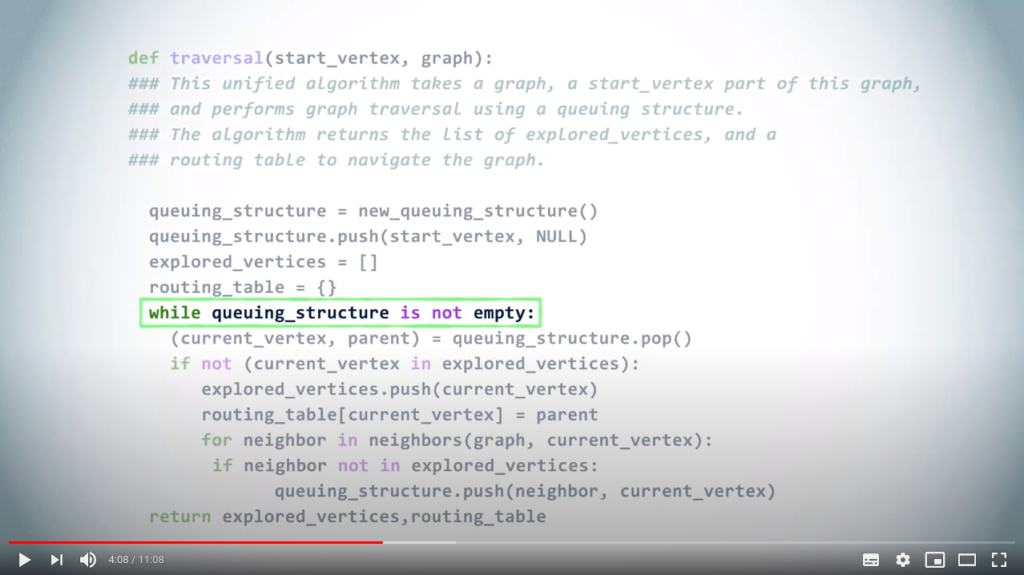
# This unified algorithm takes as arguments a graph, and a vertex of this graph from which to start the graph traversal using a queuing structure. The algorithm returns the list of explored_vertices, and a routing table to navigate through the graph.
def traversal (start_vertex, graph) :
# First we create either a LIFO or a FIFO
queuing_structure = new_queuing_structure()
# Add the starting vertex with None as parent
queuing_structure.push((start_vertex, None))
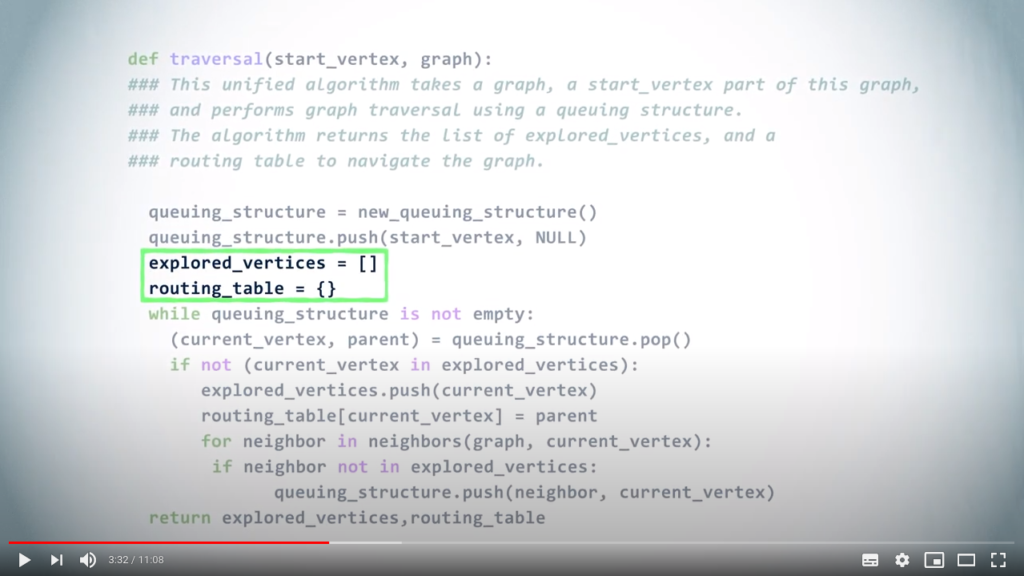
# Initialize the outputs
explored_vertices = []
routing_table = {}
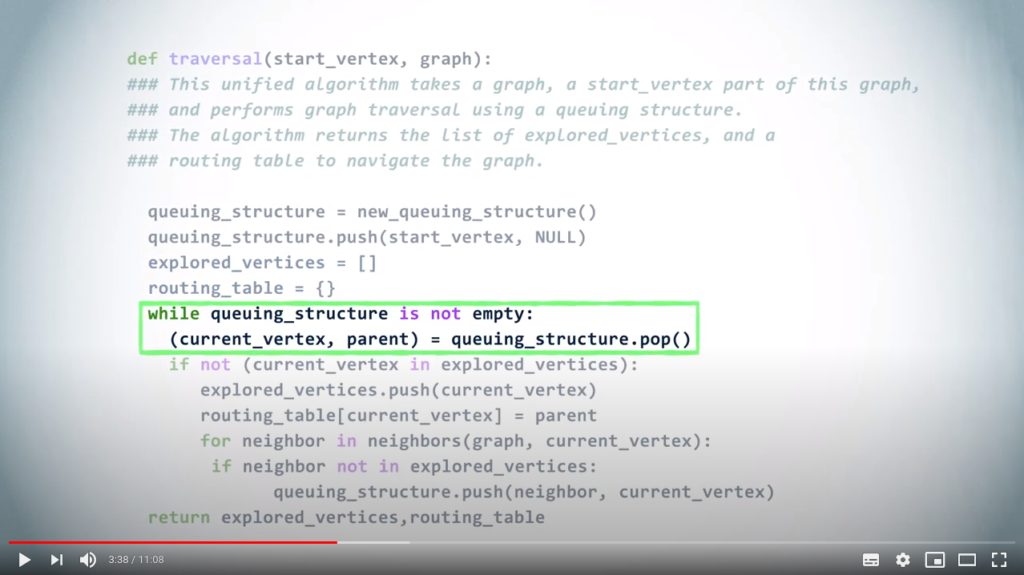
# Iterate while some vertices remain
while len(queuing_structure) > 0 :
# This will return the next vertex to be examined, and the choice of queuing structure will change the resulting order
(current_vertex, parent) = queuing_structure.pop()
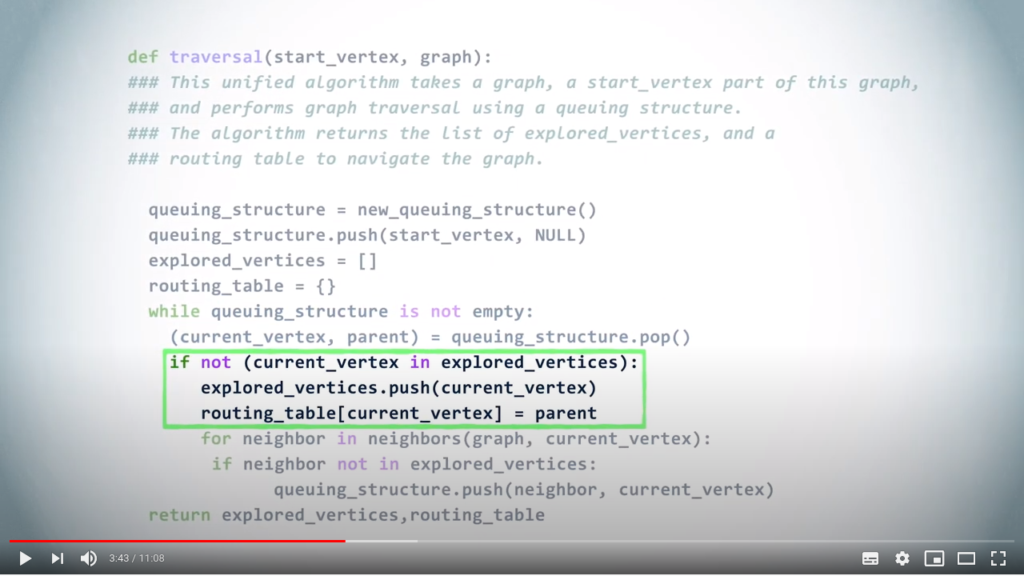
# Tests whether the current vertex is in the list of explored vertices
if current_vertex not in explored_vertices :
# Mark the current_vertex as explored
explored_vertices.append(current_vertex)
# Update the routing table accordingly
routing_table[current_vertex] = parent
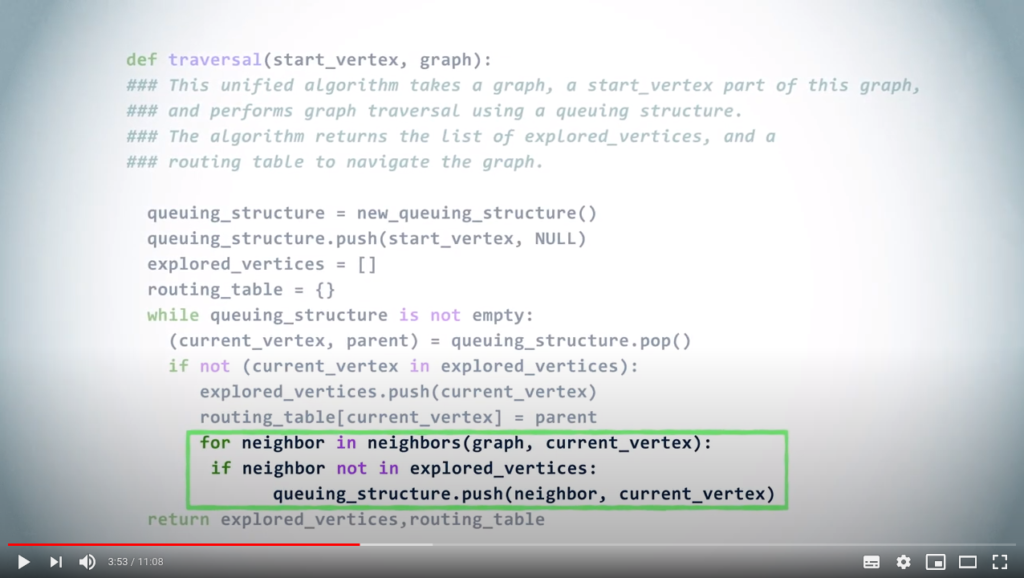
# Examine neighbors of the current vertex
for neighbor in neighbors(graph, current_vertex) :
# We push all unexplored neighbors to the queue
if neighbor not in explored_vertices :
queuing_structure.push((neighbor, current_vertex))
return explored_vertices, routing_table
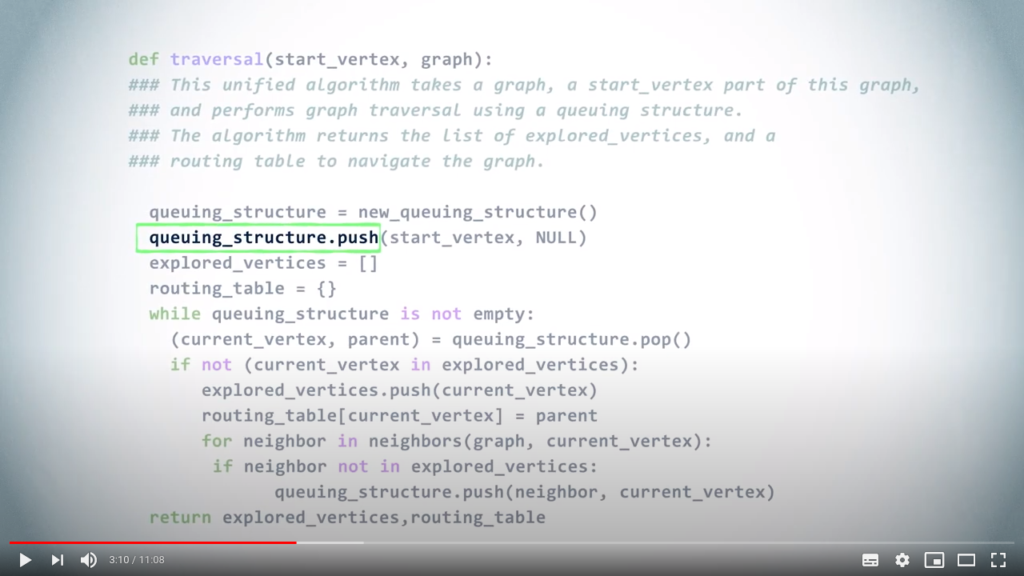
Once we have chosen a queuing structure, we first push the starting vertex. Here, we are interested in building the routing table as well, so, in the queuing structure we push couples made of the vertex and its parent in the corresponding spanning tree. Since the starting vertex has no parent, we use NULL instead here.
We also create the initially empty set of explored vertices, and the initially empty routing table.
Then, as long as the queuing structure is not empty, we pop a vertex and its parent.
If this vertex is not already explored, we mark it as explored and we update the routing table by associating the vertex with its parent.
Finally, we add all unexplored neighbors of the vertex to the queuing structure, with the current vertex as parent. If the vertex we popped from the queuing structure was already explored, we simply ignore it.
The algorithm finishes when the queuing structure is finally empty. Depending on the choice of the queuing structure: a LIFO or a FIFO, we obtain a DFS or a BFS.
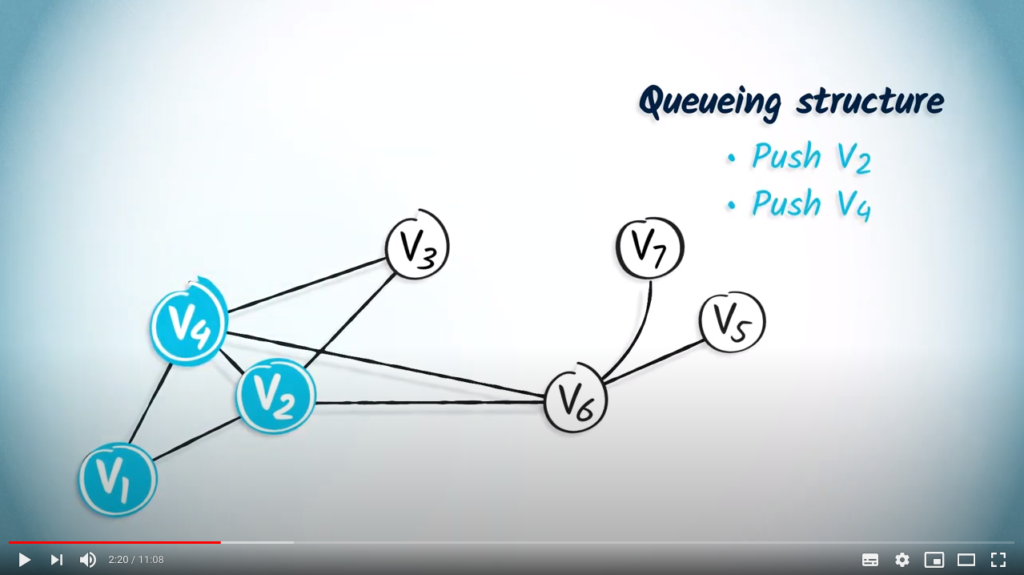
Let’s illustrate this using an example.
Application with DFS
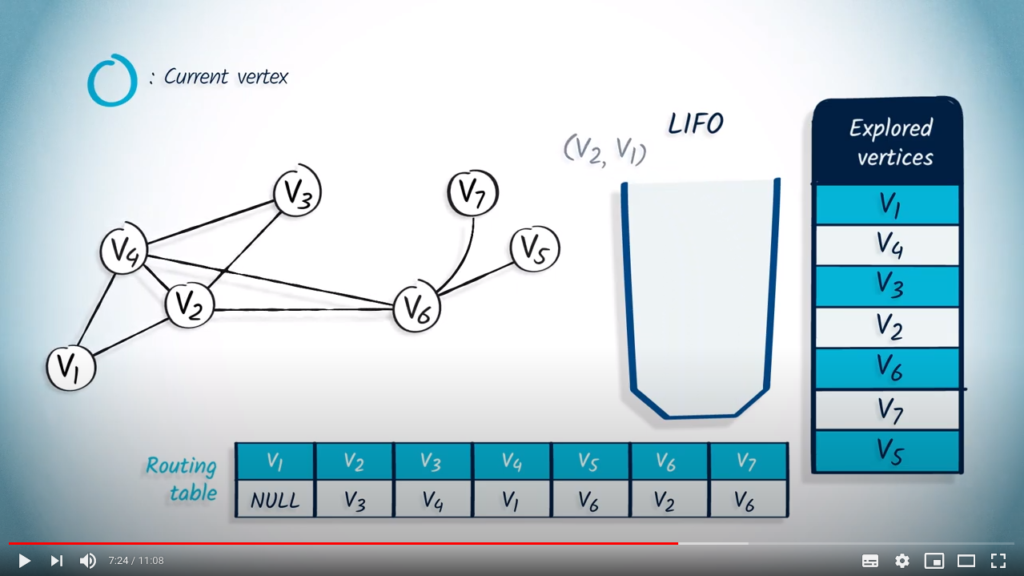
Let’s perform a DFS from . We show the content of the LIFO as we traverse the graph. The list of explored vertices is on the right. We also show the routing table.
We begin by pushing the starting vertex into the LIFO, with NULL as its parent.
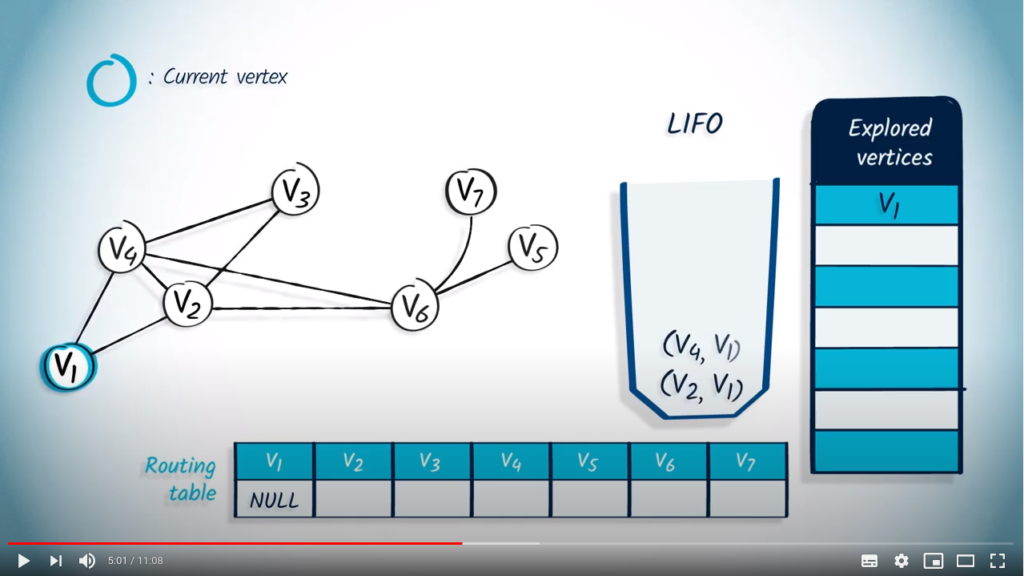
We pop a vertex and its parent from the LIFO, , and NULL. As is not in the list of explored vertices, we mark it as explored and update the entry corresponding to in the routing table by setting it to NULL. Then, we push in the LIFO all the neighbors of that are not in the list of explored vertices, which are and , with their parent .
We remove an element from the LIFO, which is , with as parent, because it’s the last element that was added. is not in the list of explored vertices, so we mark it as explored, and update the entry corresponding to in the routing table by setting it to . Next, we push all its unexplored neighbors into the LIFO. As has already been explored, we push , then in the LIFO, with as parent.
The next element to be removed is and its parent . As wasn’t previously explored, we add it to the list of explored vertices and update the routing table accordingly. Among the neighbors of , only hasn’t been explored, so we push in the LIFO, with as parent.
We remove and its parent from the LIFO. wasn’t previously explored, so we mark it as explored and update the routing table by setting the corresponding entry to . Among the neighbors of , only hasn’t been explored, so we push with as parent in the LIFO.
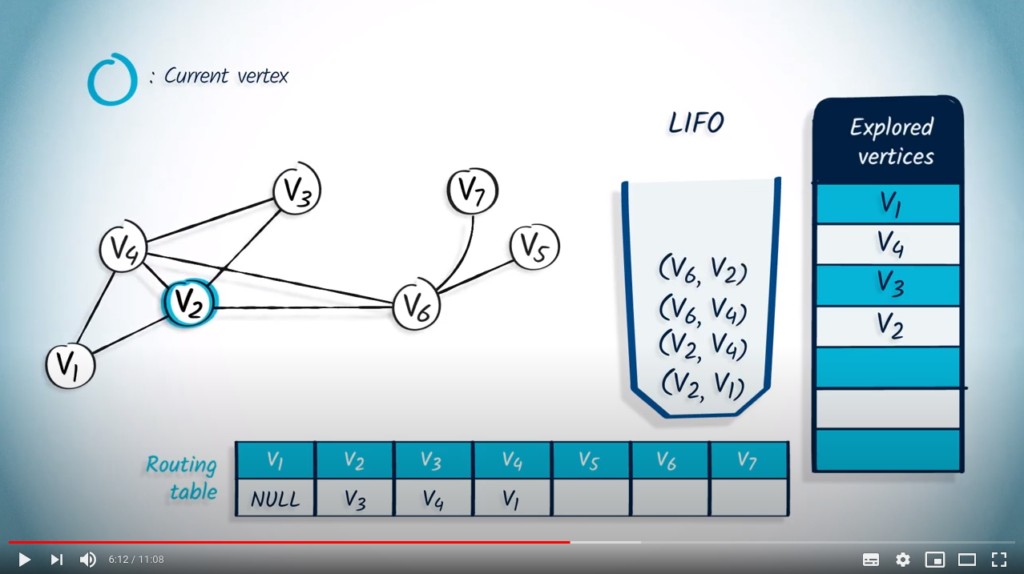
The next element to be removed is and its parent . wasn’t previously explored, so we mark it and update the routing table. The unexplored neighbors of are and , so we push them into the LIFO with as parent.
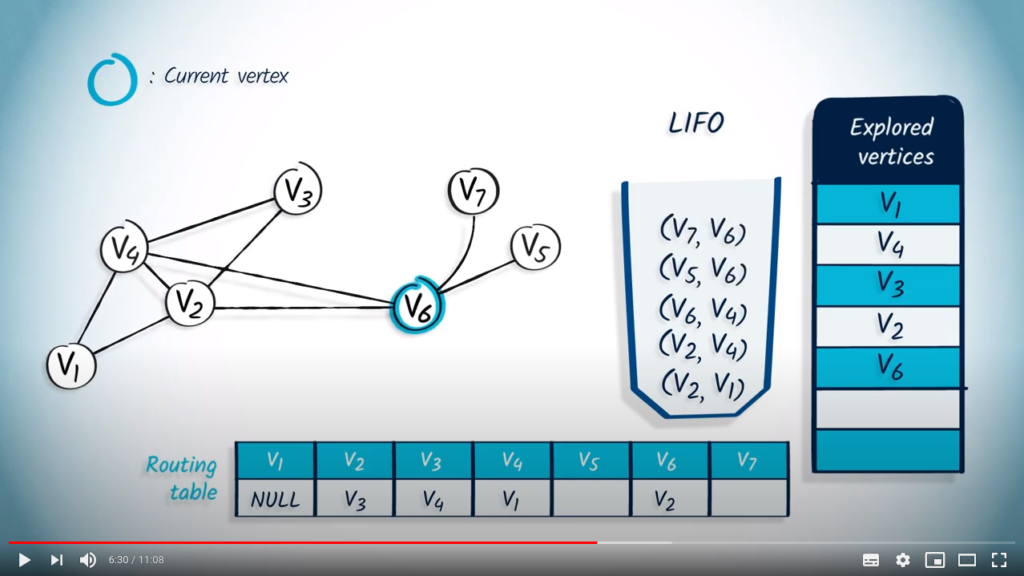
We then remove with its parent . As wasn’t previously explored, we mark it as explored and update the routing table. The only neighbor of is , which was previously explored, so nothing is pushed in the LIFO.
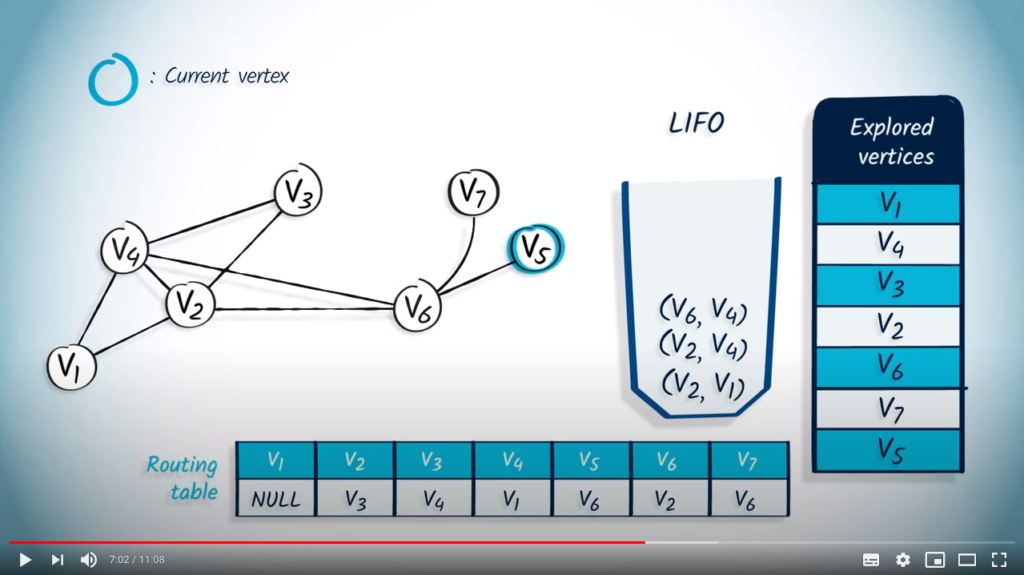
The next element that is popped from the LIFO is and its parent . wasn’t explored, so we mark it as explored and update the routing table. Here again, the only neighbor of is , which was already explored, so nothing is pushed in the LIFO.
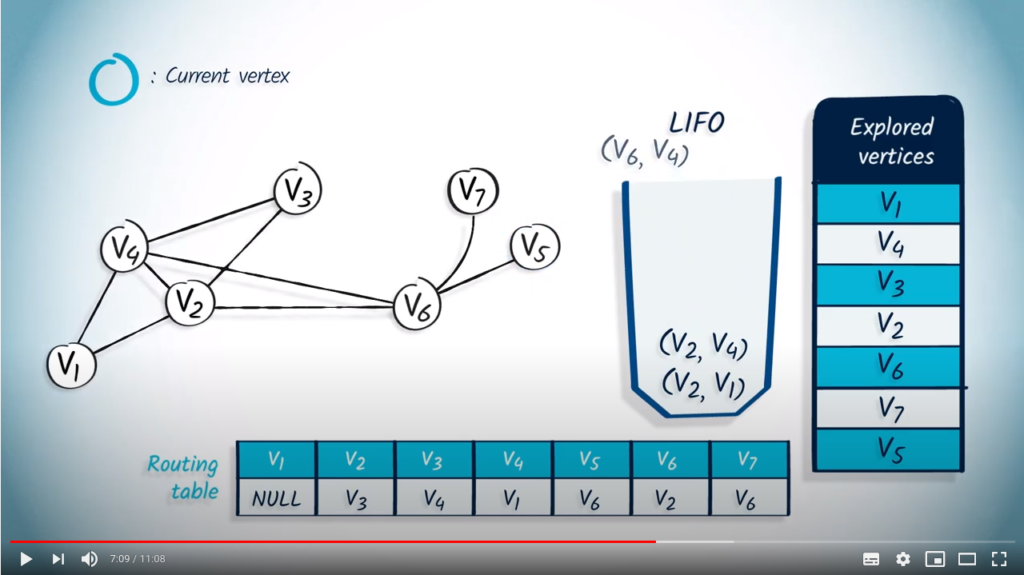
Next, we pop with as parent. As has already been explored, nothing happens.
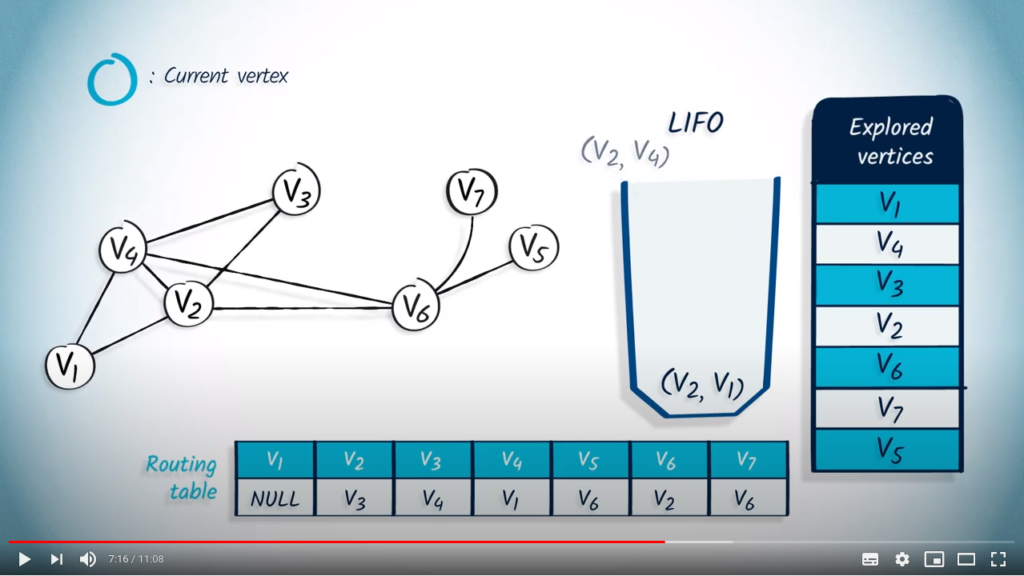
We pop with as parent, and here again, has already been explored, so nothing happens.
Finally, with as parent is popped from the LIFO, but again, has already been explored, so nothing happens.
The queuing structure is now empty, so the algorithm finishes. Notice that the fact that we’re using a LIFO directly corresponds to the fact that we keep exploring the graph until the search reaches a vertex without unexplored neighbors, in which case we go back to previously explored vertices.
Application with BFS
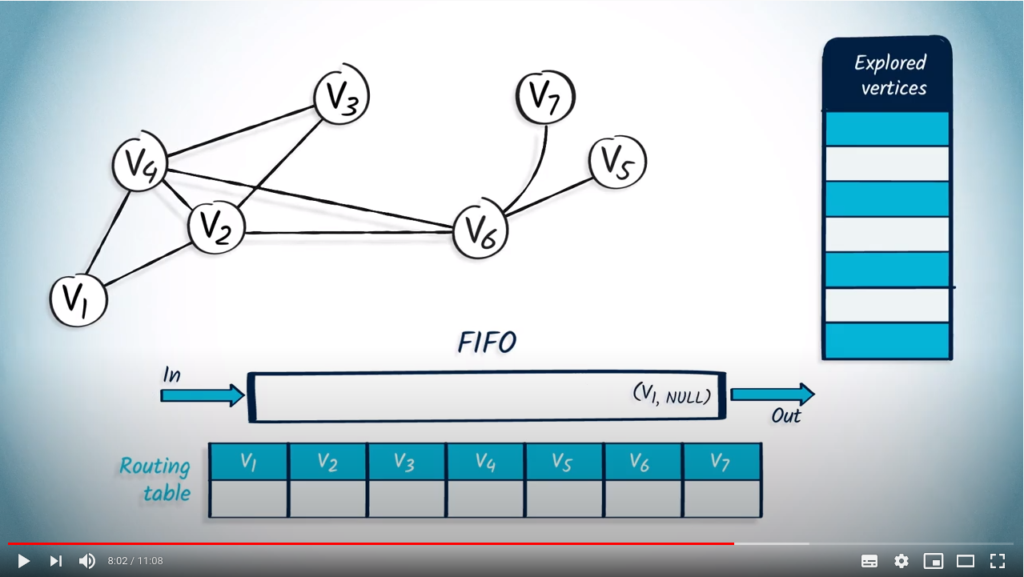
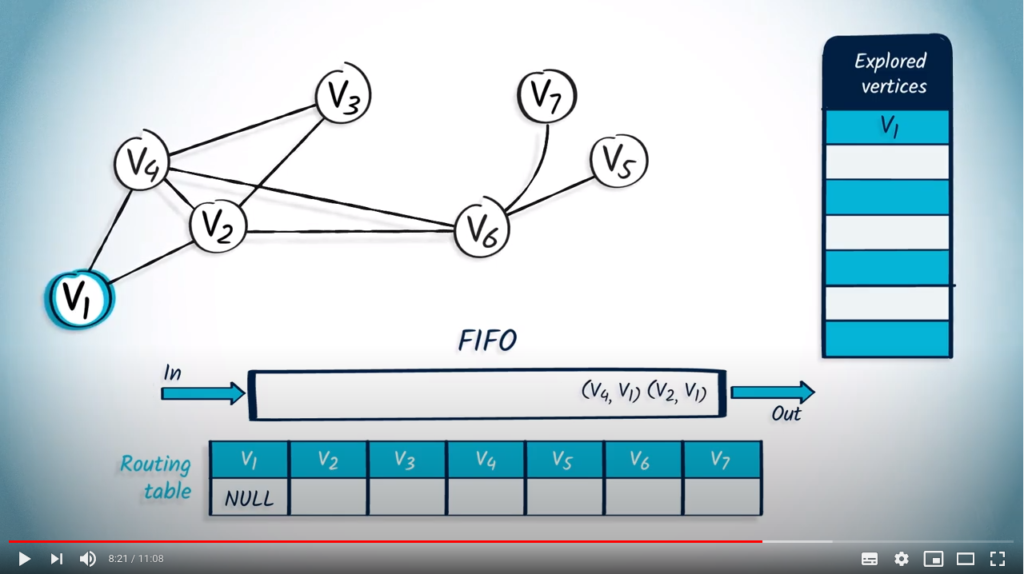
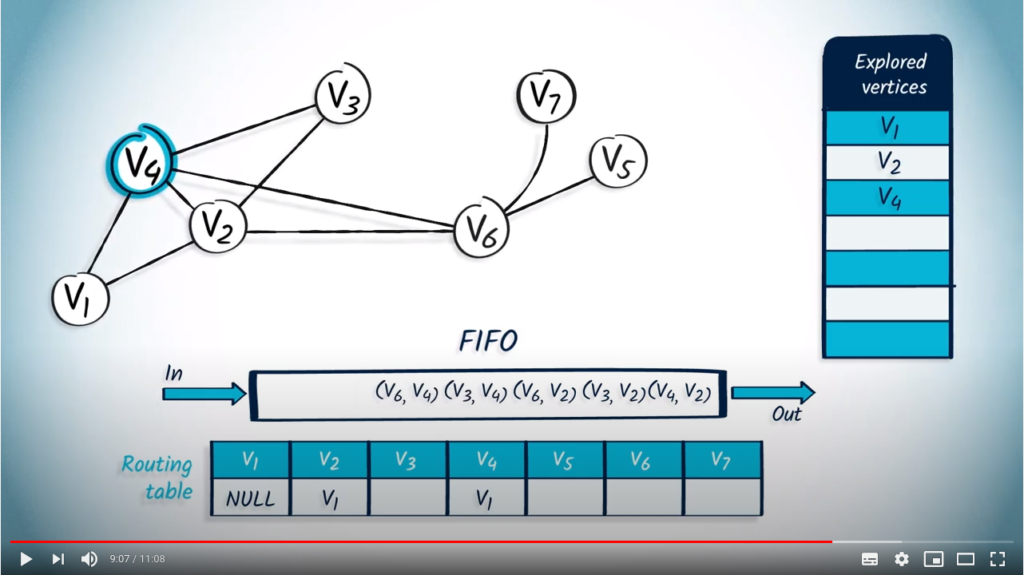
Let’s now see how we can perform a BFS from by using a FIFO. We start by pushing in the FIFO, with NULL as parent.
We pop a vertex and its parent from the FIFO, and NULL. wasn’t previously explored so we mark it, and update the routing table. Then, we push in the FIFO all unexplored neighbors of , which are and , with their parent .
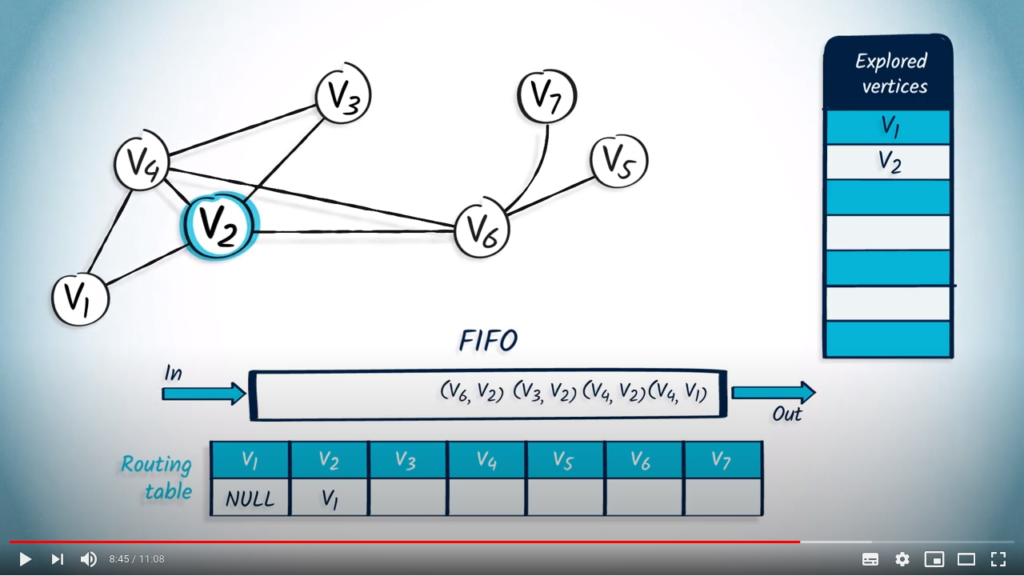
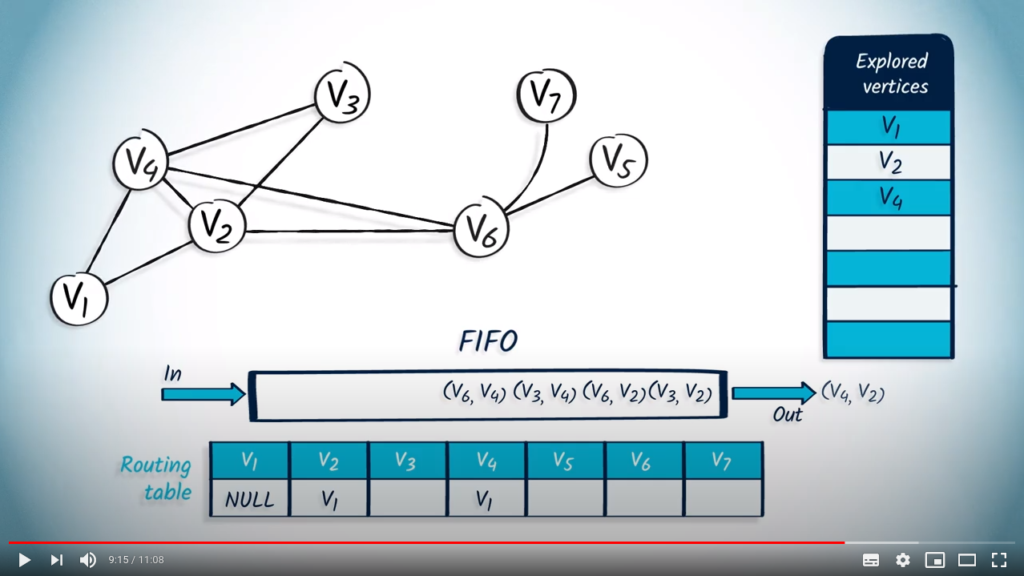
We pop an element from the FIFO, which is with as parent, because it’s the first element that was pushed. wasn’t previously explored, so we add it to the list of explored vertices and update the routing table accordingly. We push all neighbors of that are not in the list of explored vertices : , and , with as parent.
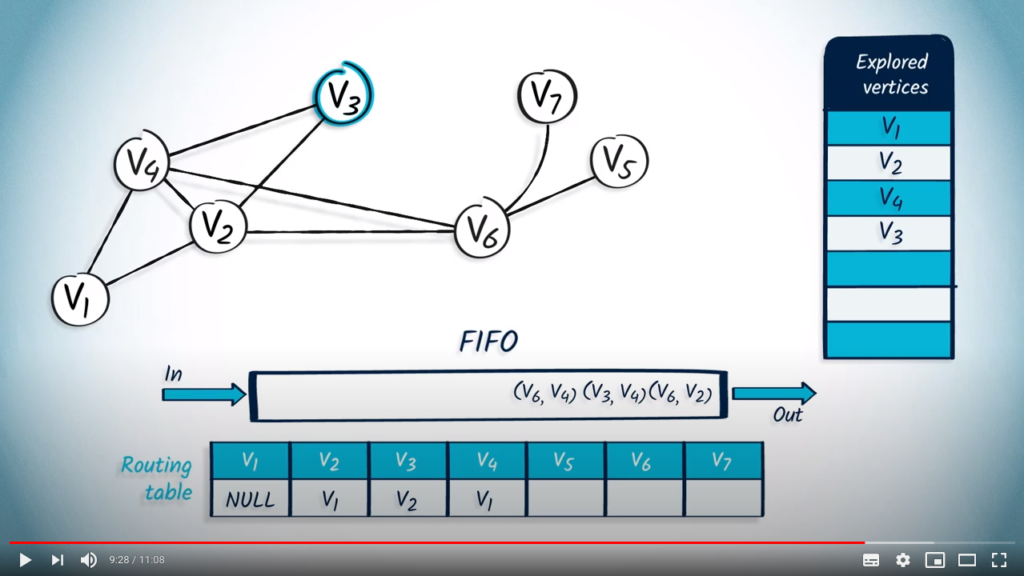
The next element to be removed from the FIFO is with as parent. As is not in the list of explored vertices, we mark it and update the routing table. Among the neighbors of , only and are not in the list of explored vertices, so we push them in the FIFO with as parent.
Next, we pop the element with as parent. has already been explored, so we move on.
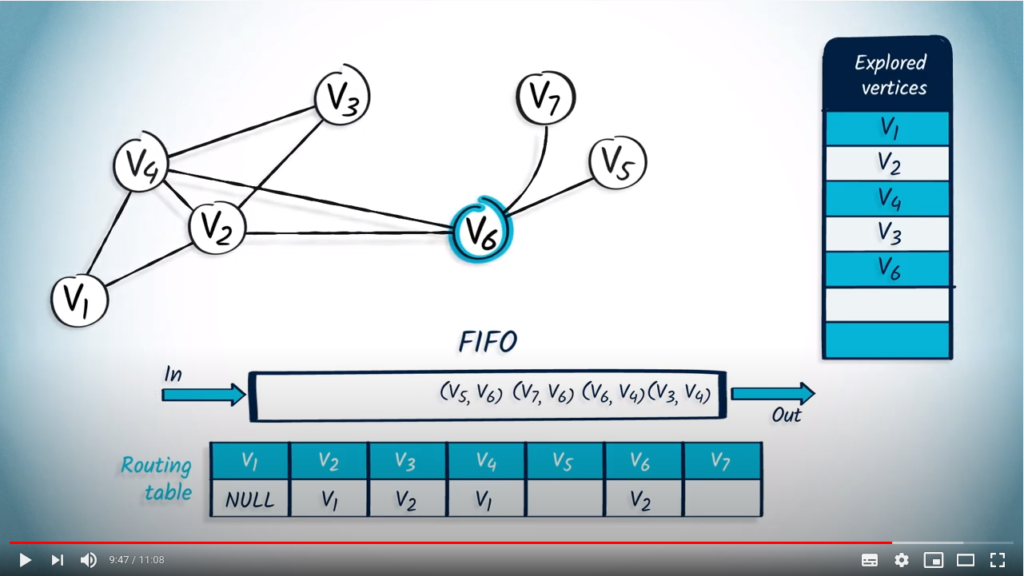
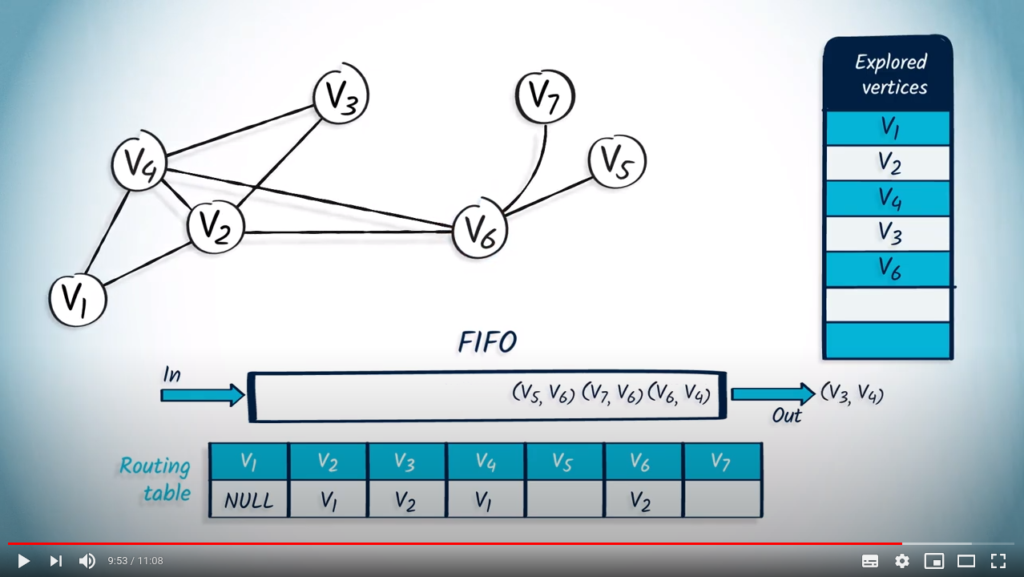
We pop the next element from the FIFO, with as parent. wasn’t explored, so we mark it and update the routing table accordingly. All neighbors of have been explored, so we continue.
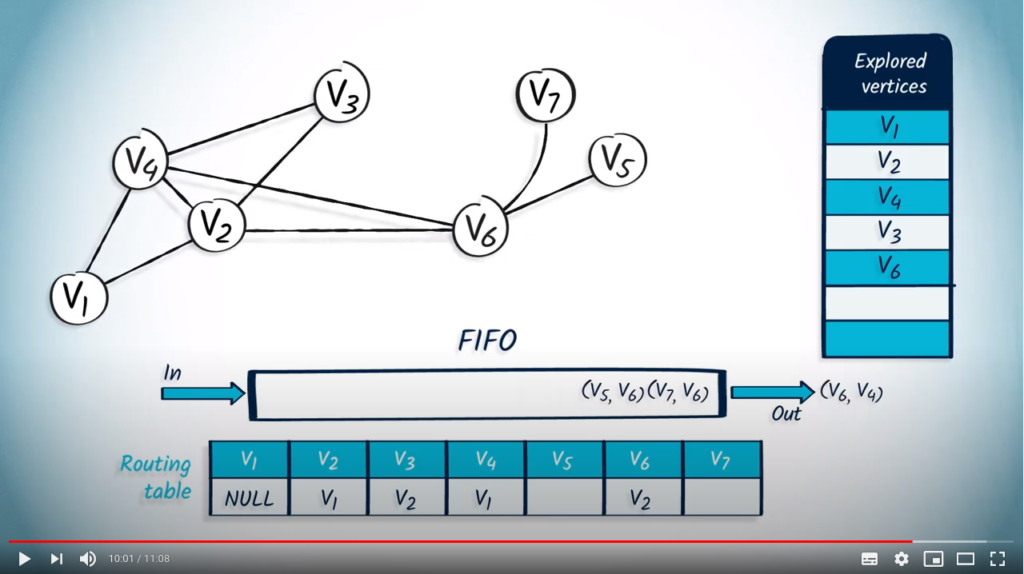
The next element to be popped from the FIFO is with as parent. This vertex wasn’t previously explored, so we mark it and update the routing table. Among the neighbors of , only two neighbors are unexplored: and , so we push them in the FIFO with as parent.
We pop the element with as parent, but as was already explored, nothing happens.
Similarly, with is popped from the FIFO, but as was already explored, we move on.
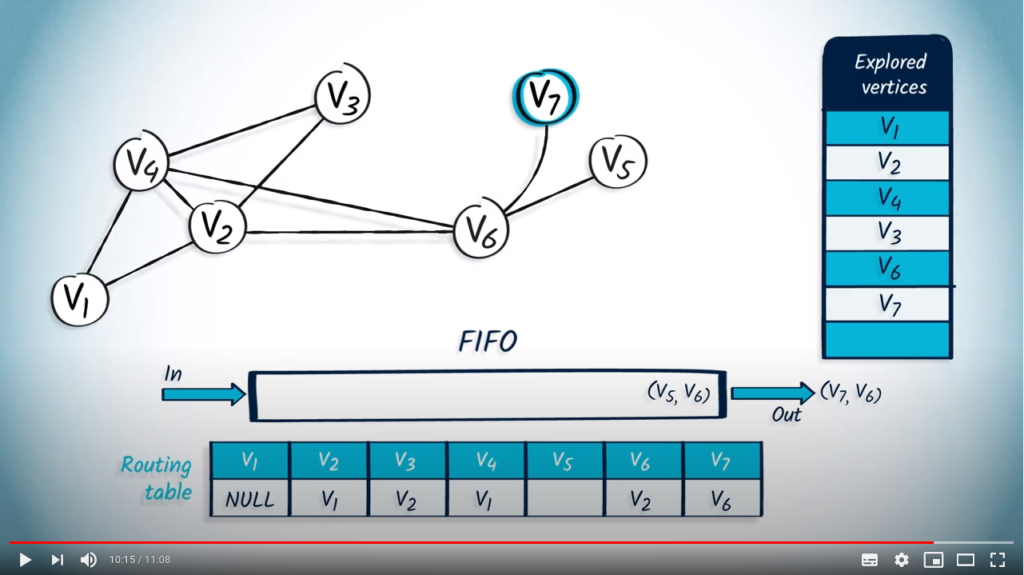
Now, we remove from the FIFO the element with as parent. was not previously explored so we mark it and update the routing table. The only neighbor of is , which was previously explored, so we continue.
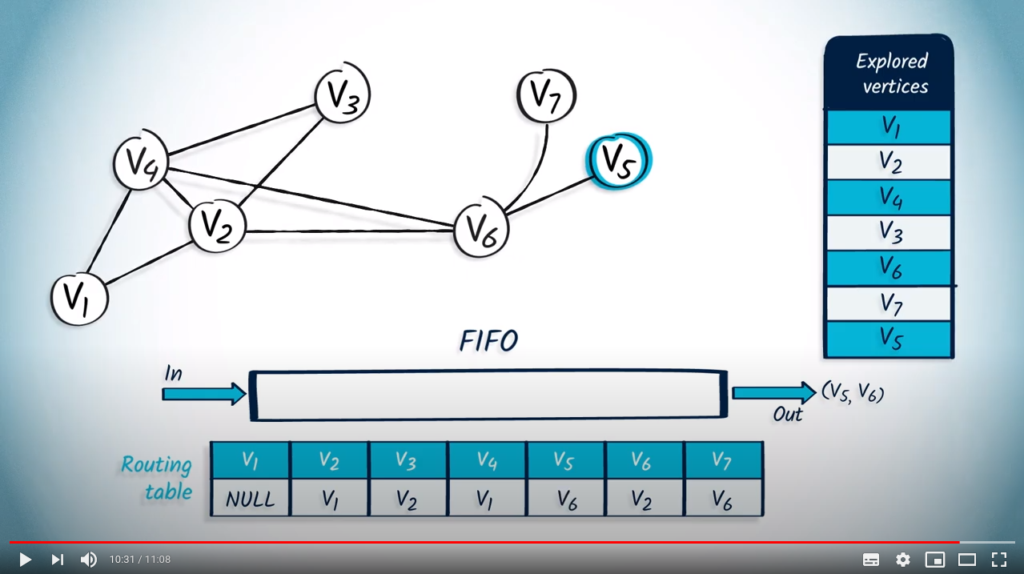
Finally, we pop with as parent from the FIFO. is not in the list of explored vertices, so we add it to this list, and update the routing table. Here again, does not have any unexplored neighbors.
The queuing structure is now empty, so the algorithm finishes. We’ve now successfully traversed the graph using BFS.
Concluding words
So, that’s how you can use queuing structures to implement DFS and BFS.
Thanks for watching! I hope you enjoyed learning about queuing structures. That’s the end of this week’s lessons. Next week, we’ll see how to deal with weighted graphs.
FIFOs and LIFOs in computer science
To appreciate the importance of these two data structures in computer science, we present two examples of real life situations in which they are used.
FIFOs in communication systems
For two people to communicate, they must send messages to each other; and for two people to understand each other, they must send messages to each other in a logical order. You will find it easier to understand the sentence A computer lets you make more mistakes faster than any other invention with the possible exceptions of handguns and Tequila than Make and tequila you than a faster the possible any exceptions handguns of invention computer lets more with other mistakes.
For machines, it’s the same: order is important, and must be taken into account. Some communication models (others are much more complex) use queues for this purpose. Imagine a model in which we have a computer that writes words in a queue, and a computer that reads them. If computer sends the words in order, then will read them in the same order (because the first element inserted in a queue is also the first to leave it), and communication will be possible.
You may be wondering why go through a FIFO and not send the information directly? The advantage is that computers and do not necessarily go at the same speed (quality of the processor, network card…). Thus, if computer sends messages to computer very quickly (directly), the latter will miss some of them. Going through a queue allows you to store messages, in order, to avoid these synchronization problems.
LIFOs in programming languages
When an operating system runs a program, it allocates some memory to it so that it can do its calculations correctly. This memory is generally divided into two areas: the heap that stores data, and the stack that allows (among other things) to call functions in programs.
In most programming languages, when a function f(a, b) is called at a code location, the following (simplified) sequence occurs:
The return address is pushed on the stack. This will allow coming back right after f is called once its execution ends.
Argument a is pushed on the stack.
Argument b is pushed on the stack.
The processor is told to process the code of f.
We pop an element from the stack to get b.
We pop an element from the stack to get a.
The code of f is executed.
Once f is over, we pop an element from the stack to get the return address and go back to when f was called.
The processor is told to jump to that address.
But why use a stack instead of variables to pass this information? Well, the processor doesn’t know the details of f! It is possible that f uses another function g for example. If variables were used, the return address of f would be overwritten by the return address of g, and when g was finished, we could never return to the time of the call of f.
How about a FIFO then? Here again, the problem occurs if f calls a function g. As the return address of f is put before that of g in the queue, when it is necessary to return from the call to g, the processor will get instead the return address of f (the oldest in the queue)! We will therefore never execute the f code located after the g call.
To go further
Queuing theory gives more results on queues (expected time before being popped, etc.) and has many applications.




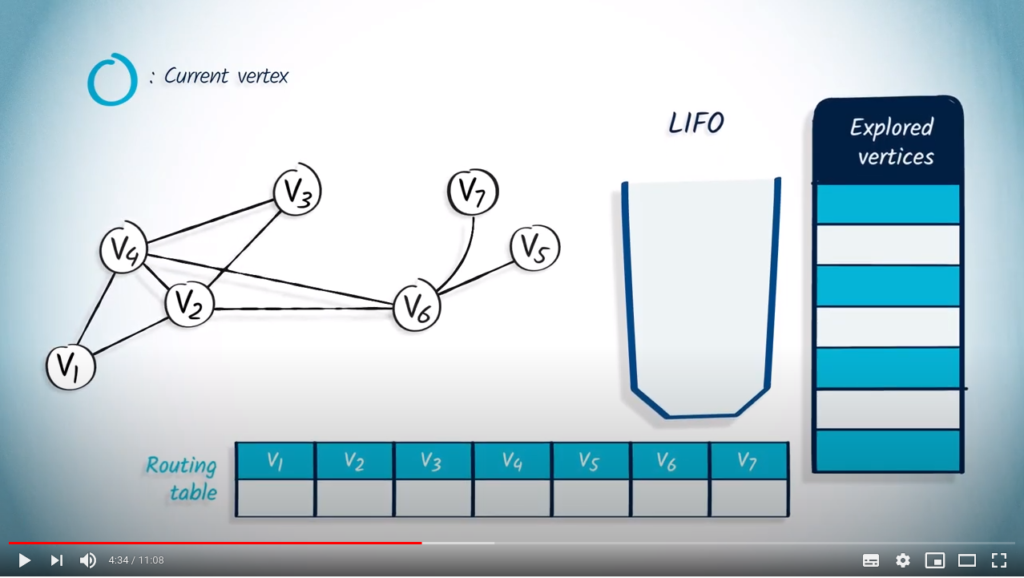
 . We show the content of the LIFO as we traverse the graph. The list of explored vertices is on the right. We also show the routing table.
. We show the content of the LIFO as we traverse the graph. The list of explored vertices is on the right. We also show the routing table.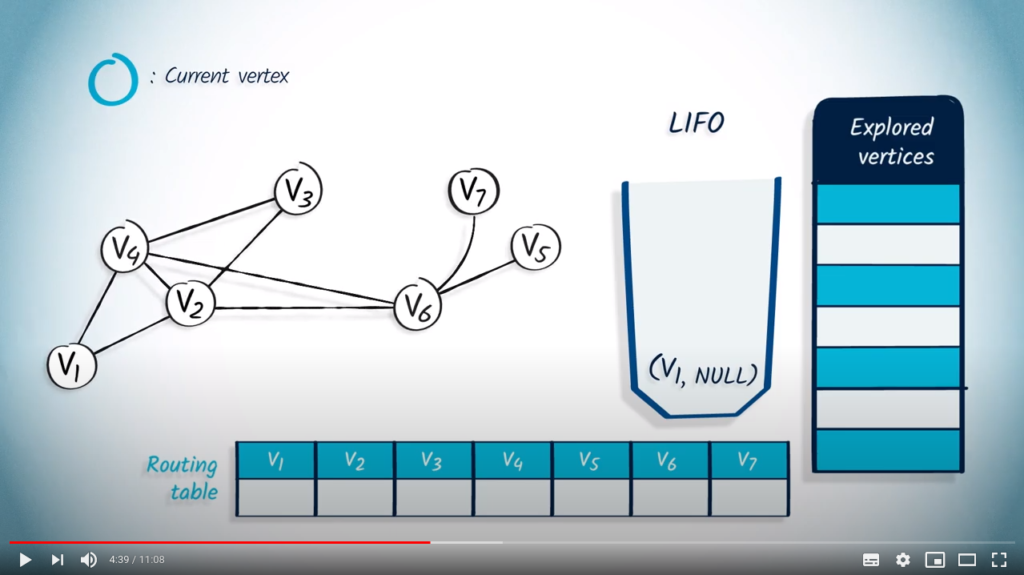
 and
and  , with their parent
, with their parent 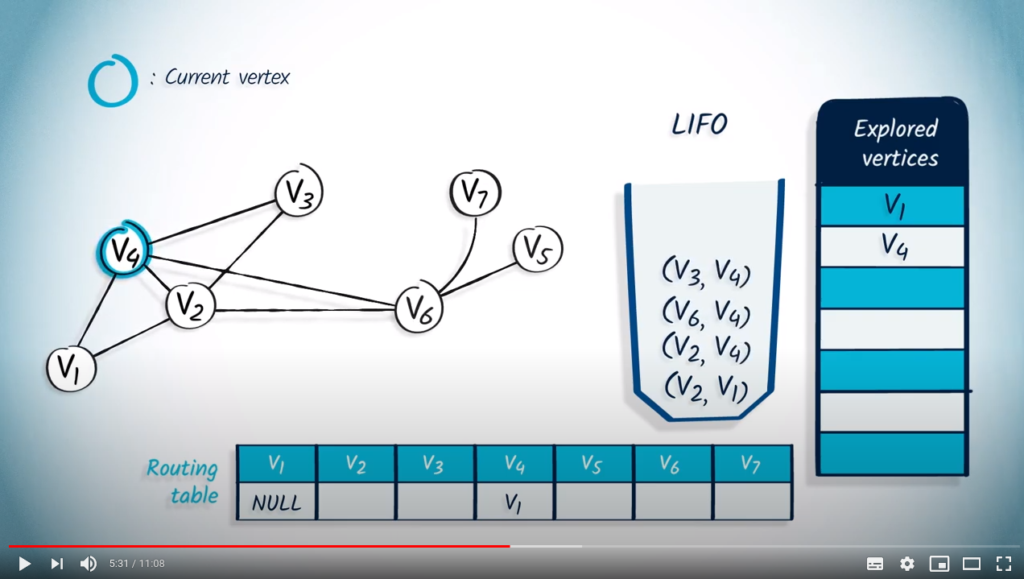
 then
then  in the LIFO, with
in the LIFO, with 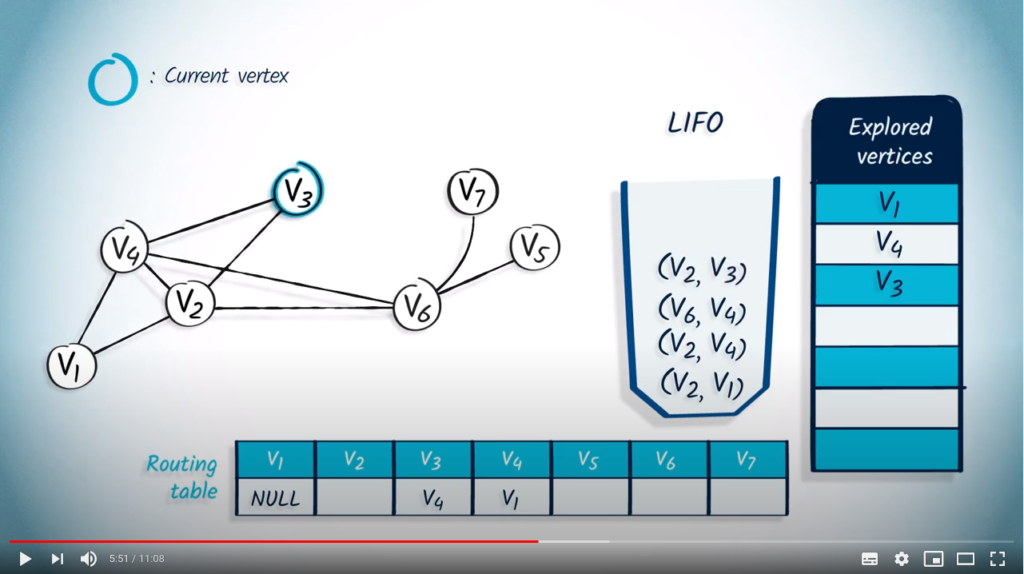
 and
and  , so we push them into the LIFO with
, so we push them into the LIFO with 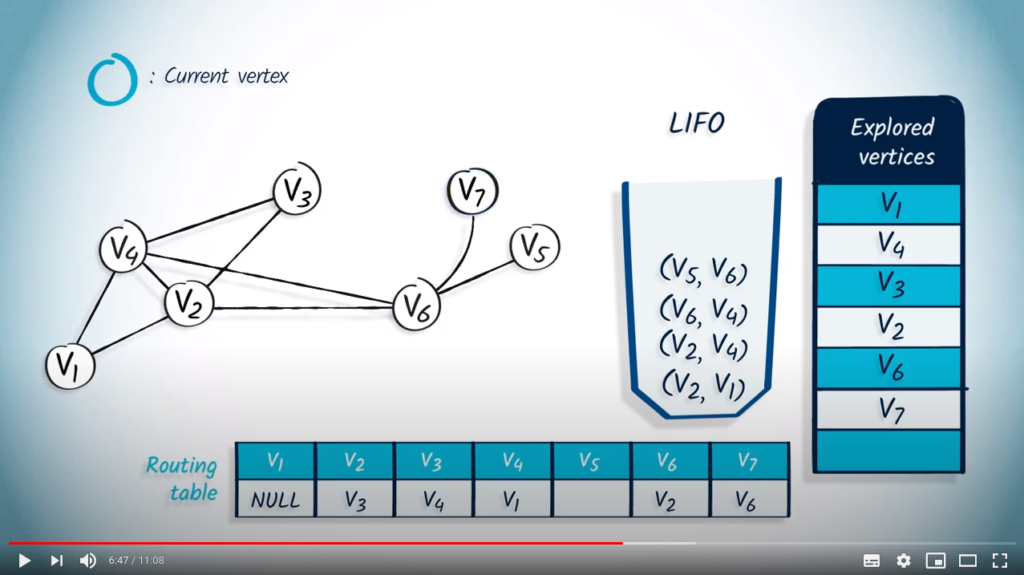
 that writes words in a queue, and a computer
that writes words in a queue, and a computer  that reads them. If computer
that reads them. If computer 